Retrieval-Augmented Generation (RAG): Everything You Need to Know
6.3 min read
By: Harsha Naru & Karthick Selvam

Imagine asking an AI (like GPT) to summarise last week’s most exciting news or give you insights about a financial report you are clueless about. Traditional AI models might provide generic responses or outdated information. That’s where Retrieval-Augmented Generation (RAG) comes in, making AI smarter, faster, and more relevant.
In this blog, we’ll explain RAG, how it works, and why it will be a game-changer in the upcoming years.
What is RAG?
At its core, RAG combines two powerful concepts: retrieval and generation. Think of it as a hybrid approach to AI that blends the ability to fetch relevant information with the creativity to generate human-like responses. By combining the power of information retrieval with generative AI models, RAG enables systems to provide accurate, contextually relevant, and up-to-date responses, addressing some of the core limitations of traditional generative models.
Here’s a simple analogy:
Let’s say you’re writing an essay about climate change. Instead of relying solely on your memory (like most AI models do), you search for recent articles, scientific papers, or blog posts to support your points. After gathering this information, you then write your essay in your own words. This combination of research and creativity is precisely how RAG works. In future blogs, we will discuss Agentic RAG, which can automate the above example.
How Does RAG Work?
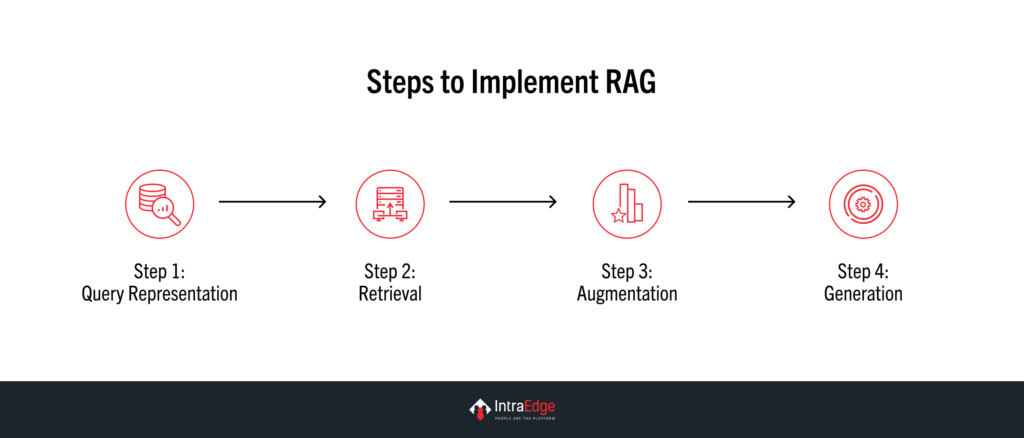
RAG has two key components:
- Retriever: The retriever is a dense or sparse vector search mechanism responsible for retrieving relevant information from a knowledge base or external source. Tools like FAISS, OpenSearch, or Pinecone often power this component, with embeddings generated by pre-trained models like Sentence-transformers BERT or OpenAI’s embeddings API.
- Generator: A language model (e.g., GPT-4, T5, or LLaMA3) synthesizes retrieved information into coherent, natural-language responses. It interprets the query and structures its response based on retrieved data.
- Step 1: Query Representation
The input query is converted into a vector representation using embedding models like BERT or OpenAI embeddings. - Step 2: Retrieval
The retriever searches a document corpus or database for the most relevant information (context passages). This is often performed via similarity search methods such as cosine similarity in vector space. - Step 3: Augmentation
Retrieved documents are appended to the query and passed into the generator as additional context. - Step 4: Generation
The generator creates a human-like response by leveraging the query and the retrieved documents.
Why Does RAG Matter?
RAG addresses some of the biggest challenges in AI:
- Up-to-date Information: Many AI models are trained on months or even years-old data. RAG pulls in real-time information, ensuring responses are current.
- Contextual Relevance: By retrieving data tailored to your question, RAG avoids generic or irrelevant answers.
- Efficiency: Instead of sifting through hundreds of sources yourself, RAG summarizes information in seconds.
RAG in Action: Real-World Applications
Here are some ways RAG is transforming industries:
- Customer Support: AI chatbots powered by RAG can provide accurate, personalized responses by pulling data from FAQs, product manuals, and user forums.
- Education: RAG helps students and researchers by fetching the latest studies, tutorials, or lecture notes for complex topics.
- Healthcare: Doctors can get AI-powered insights from the latest medical journals, ensuring evidence-based decisions.
RAG-based Resume Matching
We have developed a prototype of a RAG-based resume-matching application using dummy IT resumes and candidate data. This application was capable of filtering through candidates when a natural query or job description was provided. This approach is a context-aware solution that could truly understand the nuanced connections between job descriptions and candidate profiles. Everything we have used is open source. The workflow and the output from the PoC are shown in the pictures below.
![]()

The tech stack used for this particular use case includes Ollama-Llama3.1 8B as the core language model, Sentence Transformers for semantic embedding, LlamaIndex as the orchestration framework, and FAISS as the vector store. The core of our approach was elegantly simple yet powerful. When a job description or natural language query is input, the system does more than just keyword matching. It:
- Transforms the query into a semantic embedding
- Retrieves the top 5 most contextually relevant resume summaries
Passes these summaries to the LLM in an extended context mode
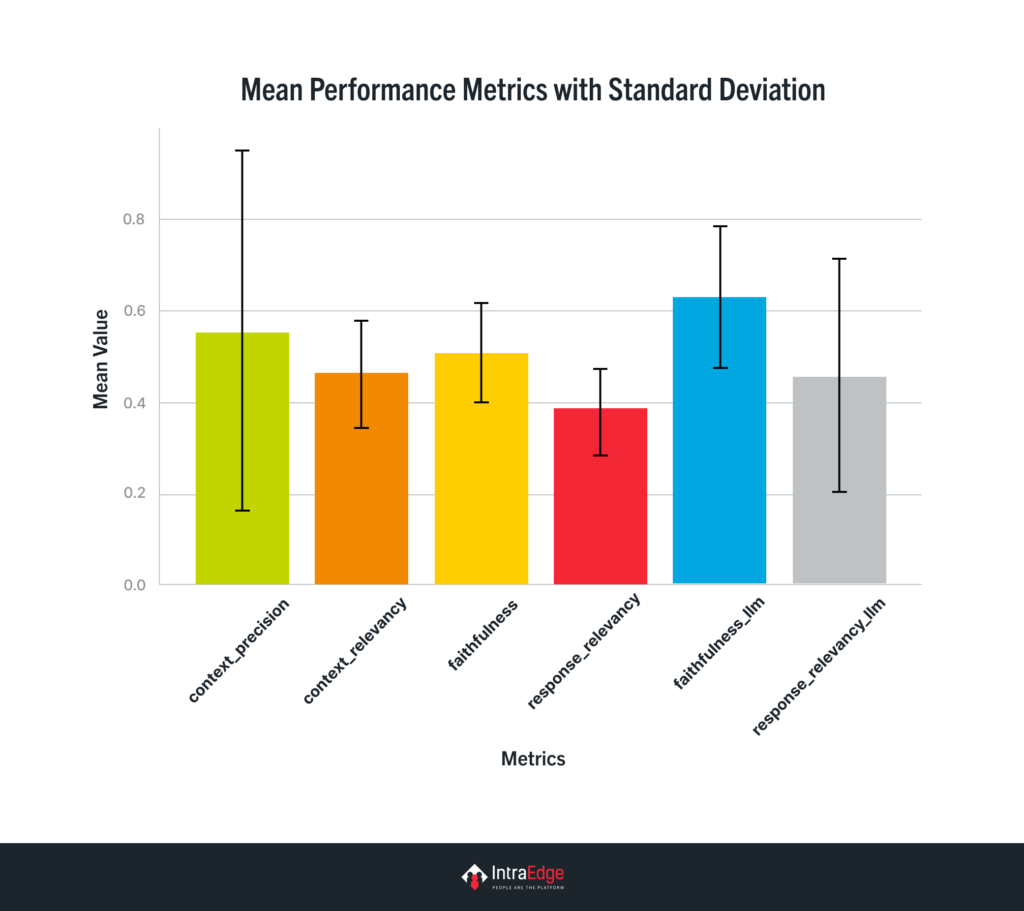
The proposed RAG system was evaluated without traditional ground truth data. Instead, we evaluated it based on four key metrics:
- Context Relevance measures how well the retrieved contexts align with the query. A significant context relevancy score suggests the retrieval remains within the intended topic.
- Context Precision is a metric that shows how many retrieved pieces of information (nodes/chunks) are relevant to the query. This implies how well the model picks out only the most relevant information for the user’s query.
- Faithfulness measures how accurately the response reflects the factual details from the retrieved information. Ensures that the generated content does not introduce any false or misleading information, i.e., hallucinations
- Response Relevance measures how well the response aligns with the query. A significant relevancy score suggests that the reaction remains within the intended topic.
Advanced Strategies and Techniques
Chunk Size Optimization – Choosing the right chunk size is considered crucial for balancing context preservation and retrieval speed. Various chunk sizes should be experimented with, and their impact on retrieval efficiency and contextual relevance must be assessed.
Query Transformations – Queries can be transformed to improve retrieval by employing techniques such as:
- Query Rewriting: Queries are reformulated for clarity.
- Sub-query Decomposition: Complex queries are split into smaller, manageable components.
- Step-back Prompting: Queries are broadened to retrieve more contextual data.
- Hypothetical Document Embeddings (HyDE): Hypothetical questions are created to improve query-data matching.
Semantic Chunking—Documents are divided into semantically coherent sections rather than fixed-size chunks. NLP techniques are utilized to identify topic boundaries and create meaningful retrieval units.
Fusion Retrieval – Keyword-based and vector-based retrieval methods are combined to ensure comprehensive results. Both approaches are leveraged to achieve a broader scope of retrieval.
Reranking – Scoring mechanisms are applied to refine the ranking of retrieved results
- Cross-Encoder Models: Queries and retrieved contexts are jointly encoded for similarity scoring.
- Metadata-enhanced Ranking: Metadata is incorporated into scoring for nuanced ranking.
- LLM-based Scoring: Results are scored using language models.
Agents—Different tools, functions, and LLM calls are built, which can be leveraged in the RAG system for use cases such as web search, GitHub retrieval, Wolfram calculator, financial charts analyzer, image scraping, and many more.
Conclusion
RAG is revolutionizing how organizations approach problem-solving, decision-making, and customer interactions. By combining the creative power of large language models with precise information retrieval, we’re witnessing a new era of contextually aware artificial intelligence.
Modern businesses crave personalized experiences, and RAG delivers. Our technology enables AI systems to provide razor-sharp, context-aware responses that feel remarkably human. Whether you’re in healthcare, finance, or customer service, RAG means more intelligent, more relevant interactions.
We’re seeing a dramatic shift in how companies integrate AI. Tools like LangChain, Ollama and Hugging Face make RAG more accessible than ever, allowing businesses of all sizes to build sophisticated knowledge-driven systems. From complex document search to intelligent customer support, RAG is no longer a luxury—it’s a necessity or a tool.
The future is advanced, multimodal, and agentic. We’re looking at systems that will seamlessly integrate text, images, audio, and video to provide unprecedented contextual understanding. But with great power comes great responsibility—we’re equally committed to addressing critical ethical considerations around data privacy and potential biases.
Imagine asking an AI (like GPT) to summarise last week’s most exciting news or give you insights about a financial report you are clueless about. Traditional AI models might provide generic responses or outdated information. That’s where Retrieval-Augmented Generation (RAG) comes in, making AI smarter, faster, and more relevant.
In this blog, we’ll explain RAG, how it works, and why it will be a game-changer in the upcoming years.
What is RAG?
At its core, RAG combines two powerful concepts: retrieval and generation. Think of it as a hybrid approach to AI that blends the ability to fetch relevant information with the creativity to generate human-like responses. By combining the power of information retrieval with generative AI models, RAG enables systems to provide accurate, contextually relevant, and up-to-date responses, addressing some of the core limitations of traditional generative models.
Here’s a simple analogy:
Let’s say you’re writing an essay about climate change. Instead of relying solely on your memory (like most AI models do), you search for recent articles, scientific papers, or blog posts to support your points. After gathering this information, you then write your essay in your own words. This combination of research and creativity is precisely how RAG works. In future blogs, we will discuss Agentic RAG, which can automate the above example.
How Does RAG Work?
RAG has two key components:
- Retriever: The retriever is a dense or sparse vector search mechanism responsible for retrieving relevant information from a knowledge base or external source. Tools like FAISS, OpenSearch, or Pinecone often power this component, with embeddings generated by pre-trained models like Sentence-transformers BERT or OpenAI’s embeddings API.
- Generator: A language model (e.g., GPT-4, T5, or LLaMA3) synthesizes retrieved information into coherent, natural-language responses. It interprets the query and structures its response based on retrieved data.
- Step 1: Query Representation
The input query is converted into a vector representation using embedding models like BERT or OpenAI embeddings. - Step 2: Retrieval
The retriever searches a document corpus or database for the most relevant information (context passages). This is often performed via similarity search methods such as cosine similarity in vector space. - Step 3: Augmentation
Retrieved documents are appended to the query and passed into the generator as additional context. - Step 4: Generation
The generator creates a human-like response by leveraging the query and the retrieved documents.
Why Does RAG Matter?
RAG addresses some of the biggest challenges in AI:
- Up-to-date Information: Many AI models are trained on months or even years-old data. RAG pulls in real-time information, ensuring responses are current.
- Contextual Relevance: By retrieving data tailored to your question, RAG avoids generic or irrelevant answers.
- Efficiency: Instead of sifting through hundreds of sources yourself, RAG summarizes information in seconds.
RAG in Action: Real-World Applications
Here are some ways RAG is transforming industries:
- Customer Support: AI chatbots powered by RAG can provide accurate, personalized responses by pulling data from FAQs, product manuals, and user forums.
- Education: RAG helps students and researchers by fetching the latest studies, tutorials, or lecture notes for complex topics.
- Healthcare: Doctors can get AI-powered insights from the latest medical journals, ensuring evidence-based decisions.
RAG-based Resume Matching
We have developed a prototype of a RAG-based resume-matching application using dummy IT resumes and candidate data. This application was capable of filtering through candidates when a natural query or job description was provided. This approach is a context-aware solution that could truly understand the nuanced connections between job descriptions and candidate profiles. Everything we have used is open source. The workflow and the output from the PoC are shown in the pictures below.
![]()
The tech stack used for this particular use case includes Ollama-Llama3.1 8B as the core language model, Sentence Transformers for semantic embedding, LlamaIndex as the orchestration framework, and FAISS as the vector store. The core of our approach was elegantly simple yet powerful. When a job description or natural language query is input, the system does more than just keyword matching. It:
- Transforms the query into a semantic embedding
- Retrieves the top 5 most contextually relevant resume summaries
Passes these summaries to the LLM in an extended context mode
The proposed RAG system was evaluated without traditional ground truth data. Instead, we evaluated it based on four key metrics:
- Context Relevance measures how well the retrieved contexts align with the query. A significant context relevancy score suggests the retrieval remains within the intended topic.
- Context Precision is a metric that shows how many retrieved pieces of information (nodes/chunks) are relevant to the query. This implies how well the model picks out only the most relevant information for the user’s query.
- Faithfulness measures how accurately the response reflects the factual details from the retrieved information. Ensures that the generated content does not introduce any false or misleading information, i.e., hallucinations
- Response Relevance measures how well the response aligns with the query. A significant relevancy score suggests that the reaction remains within the intended topic.
Advanced Strategies and Techniques
Chunk Size Optimization – Choosing the right chunk size is considered crucial for balancing context preservation and retrieval speed. Various chunk sizes should be experimented with, and their impact on retrieval efficiency and contextual relevance must be assessed.
Query Transformations – Queries can be transformed to improve retrieval by employing techniques such as:
- Query Rewriting: Queries are reformulated for clarity.
- Sub-query Decomposition: Complex queries are split into smaller, manageable components.
- Step-back Prompting: Queries are broadened to retrieve more contextual data.
- Hypothetical Document Embeddings (HyDE): Hypothetical questions are created to improve query-data matching.
Semantic Chunking—Documents are divided into semantically coherent sections rather than fixed-size chunks. NLP techniques are utilized to identify topic boundaries and create meaningful retrieval units.
Fusion Retrieval – Keyword-based and vector-based retrieval methods are combined to ensure comprehensive results. Both approaches are leveraged to achieve a broader scope of retrieval.
Reranking – Scoring mechanisms are applied to refine the ranking of retrieved results
- Cross-Encoder Models: Queries and retrieved contexts are jointly encoded for similarity scoring.
- Metadata-enhanced Ranking: Metadata is incorporated into scoring for nuanced ranking.
- LLM-based Scoring: Results are scored using language models.
Agents—Different tools, functions, and LLM calls are built, which can be leveraged in the RAG system for use cases such as web search, GitHub retrieval, Wolfram calculator, financial charts analyzer, image scraping, and many more.
Conclusion
RAG is revolutionizing how organizations approach problem-solving, decision-making, and customer interactions. By combining the creative power of large language models with precise information retrieval, we’re witnessing a new era of contextually aware artificial intelligence.
Modern businesses crave personalized experiences, and RAG delivers. Our technology enables AI systems to provide razor-sharp, context-aware responses that feel remarkably human. Whether you’re in healthcare, finance, or customer service, RAG means more intelligent, more relevant interactions.
We’re seeing a dramatic shift in how companies integrate AI. Tools like LangChain, Ollama and Hugging Face make RAG more accessible than ever, allowing businesses of all sizes to build sophisticated knowledge-driven systems. From complex document search to intelligent customer support, RAG is no longer a luxury—it’s a necessity or a tool.
The future is advanced, multimodal, and agentic. We’re looking at systems that will seamlessly integrate text, images, audio, and video to provide unprecedented contextual understanding. But with great power comes great responsibility—we’re equally committed to addressing critical ethical considerations around data privacy and potential biases.
